Matching Without IDs: How to Match Financial Data, From Rules to LLMs
This is the second article in our series on AI Reconciliation! Subscribe for the rest of the series!
We’ve all been there.
It’s almost the end of the day, and you want to go home. But between you and that door, there are two spreadsheets refusing to align. The unique IDs have issues, or perhaps whoever exported the file forgot to include them. Maybe you’re a finance analyst who needs your invoices to match your payments, maybe you’re in operations trying to get names in one list to match names in another list (which is of course full of typos). Or maybe you’re a manager, and your team depends on those spreadsheets matching. We all know the hours or even days this can take.
This pain is familiar in reconciliation teams across industries. Whether it’s interbank ledgers, invoicing systems, or supply-chain records, tiny mismatches inevitably lead to compliance issues, costly errors, or even undetected fraud. But why is matching so devastatingly difficult? Data lives in a perfect world, if you duplicate something on a computer, it will duplicate exactly. But the real world is far more complicated. One system might record “123 Fake St.,” another “St. Fake 123.” Invoice #50321‑A doesn’t match 50321A unless you’ve already standardized formats. Using a single rule-based lookup often fails, and so many leading finance teams have come to use a toolbox of techniques, ranging from rigid rules to fuzzy algorithms, to tame this mess.
But what are these techniques? How do they work? When is one approach better than another? Let’s dive into them together, so the next time you’re faced with two spreadsheets refusing to align, you’ll know what to do to get out that door.

Rule-Based Matching: Legends Never Die
First up: deterministic or rules-based matching. You’re likely familiar with this approach in practice. We can think of it as the finance equivalent of a checklist: “dollar amount must match, date must align, invoice number must be identical.” It’s instantly transparent—if it matches, it matches (auditors love this one simple trick!). This sort of logic underlies most ERP reconciliation engines. But it breaks in the face of small variations: extra spaces, missing suffixes, inconsistent data types. At the extremes of frustrating experiences, two cells containing the value 10 might not reconcile if one is stored as text and the other as a number. Despite its simplicity, this approach wins huge favor for its explainability. Boagent’s first matching attempt is always rule-based (our AI agent assigns the rules for you of course) precisely because of the approach’s transparency. But sometimes it doesn’t work. So, we’re forced to look for better tooling.
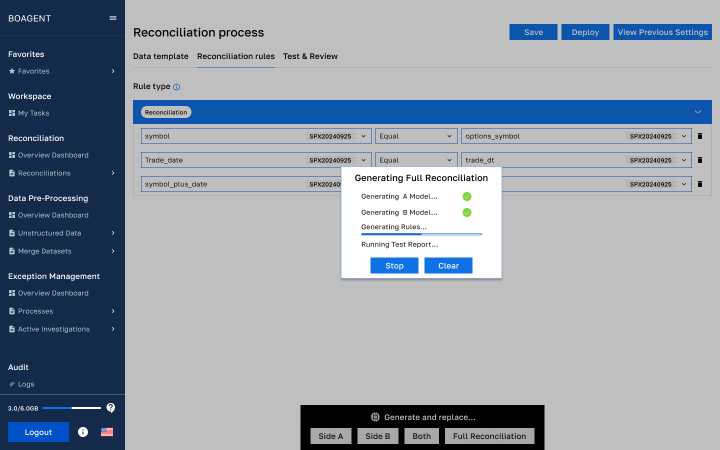
Boagent generates rules for you, trying different combinations before switching to ML techniques.
Fuzzy Match: A Former Great
Enter fuzzy matching. Rather than demanding perfection, this method gives imperfect pairs a similarity score and accepts them when they cross a threshold. A typo here, a missing hyphen there—no problem. Algorithms like Levenshtein distance (edit distance), Jaro-Winkler, and phonetic encodings like Soundex let systems catch “Smith” vs “Smyth” or “Jonathan” vs “Jonahtan” Source. Business teams use fuzzy logic to merge customer lists or match invoices despite small inconsistencies, striking a balance between flexibility and risk by fine-tuning thresholds Source. But beware: if you set the similarity bar too low, you risk matching “Robert” with “Roberta,” which might be funny at first but becomes far less entertaining when you’re explaining why a bank deposit went to the wrong person.
Probabilistic Match: A Step Beyond Fuzzy
Beyond fuzzy, probabilistic (or statistical) matching builds on multiple fields to calculate the likelihood that two records refer to the same entity. Stemming from the Fellegi–Sunter framework of the late 1960s, these methods weigh each field’s match probability. Is the surname the same? That’s strong evidence. Is the ZIP code near? Add weight. Add up all evidence and you get a match probability Source | Source. In government, health care, and customer data platforms, probabilistic matching handles messy overlaps, especially in datasets where unique identifiers are missing. It’s smarter than fuzzy matching alone, yet still interpretable (you can see field-level contributions) and easier to tune than full-blown AI models.
ML Match: Best In Class
Layered on top of that are machine learning approaches. Boagent skips over fuzzy and probabilistic techniques and goes straight to ML-match. While it’s more difficult to implement, requiring training, compute, and specialized databases, it performs far better than fuzzy and probabilistic approaches, with a similar level of transparency (we think our platform actually pushes transparency past what’s standard for fuzzy/probabilistic systems). Instead of manually weighting fields, teams train a model to predict correct matches from historical data by using patterns humans wouldn’t be able to program. ML lets systems learn that partial text overlaps plus near-equal amounts make a match, or that contextual clues, let’s say keywords in descriptions, signal equivalence. While advanced models, like the one in our platform, may use semantic embeddings, most reconciliation teams lean on simpler classifiers like random forests or gradient boosting—they integrate smoothly into workflows and provide explainable outputs Source.
Graph-Based Match: Case Specific Scalpel
Then there’s graph-based matching. Imagine representing records as nodes in a network—with edges showing potential matches. This allows you to handle complex scenarios like many-to-one or many-to-many relationships—say, one payment settling multiple invoices. Optimization algorithms, such as the Hungarian method, help find globally optimal match combinations across a dataset. This is especially useful in treasury, supply chains, or invoice payment reconciliation where relationships aren’t always one-to-one. For these specific business cases, graph-based matching really shines.
LLMs: The Next Generation (when applied with care)
Finally, at the cutting edge, large language models (LLMs) are beginning to show promise. These models understand semantics from massive text corpora and can interpret nuances that rule-based systems miss. Early use cases include using ChatGPT to normalize job titles or map invoice descriptions. One analyst reported about 95% accuracy mapping messy titles in minutes. Impressive! Yet, concerns remain around hallucination, cost, speed, and explainability. Today, LLMs are best preserved for tricky, unstructured reconciliation tasks and used alongside traditional methods.
Boagent is pioneering a new way of using LLMs in reconciliation. The agent takes control of the reconciliation, with different techniques at its disposal, and iteratively attempts to match data while maximizing explainability.
Taken together, it’s clear that no single method fits all business cases. The strongest reconciliation engines fold in layers: starting with strict rules to capture easy matches, applying fuzzy and probabilistic logic next, turning to ML for subtler patterns, and reserving graph and LLM tools for business-specific, complex tasks. It’s an elegant dance of precision and recall: automating the simple and deferring the complicated, so that you neither swim in mismatched data nor build a black box you can’t explain.
The next time you’re stuck with ID-less files, or typos, or incomplete sources, consider your business case. Does it call for pattern based matching? Maybe a graph-based approach? Or maybe you can accept an LLM’s result. And if all else fails, you can always check out Boagent.